How I Built an Automated Lead Generation System That Found 54 Insurance Prospects in 20 Minutes
A case study in using government databases, Python, and domain expertise to build prospect dossiers that most salespeople spend weeks assembling by hand.

Everyone in B2B sales is scraping LinkedIn. Everyone is buying Apollo credits. Everyone is running the same Clay enrichment workflows on the same ZoomInfo data, writing the same "I noticed your company..." cold emails to the same overworked decision-makers who stopped reading them in 2022.
I wanted to find people that nobody else was looking for.
An insurance client came to me with a problem: they wanted to break into the timber insurance market in Northern California. Specifically, they wanted to sell insurance packages (general liability, commercial auto, workers' compensation, inland marine equipment coverage) to logging companies operating in Shasta County and the surrounding North Interior region.
There were no lead lists for this. No Apollo filter for "logging contractors operating Class A Licensed Timber Operator equipment in CAL FIRE jurisdiction." No LinkedIn Sales Navigator boolean that returns the owner of a three-crew mechanized logging outfit in Cottonwood, California. This market exists almost entirely offline. These operators are running chainsaws and feller bunchers in the woods, not updating their LinkedIn profiles.
So I built a system that found them anyway.
The Insight Nobody Else Had
Here's the thing about niche B2B markets: the people you're trying to reach have already registered themselves with the government. Multiple times. Across multiple agencies. And every single one of those registrations is public record.
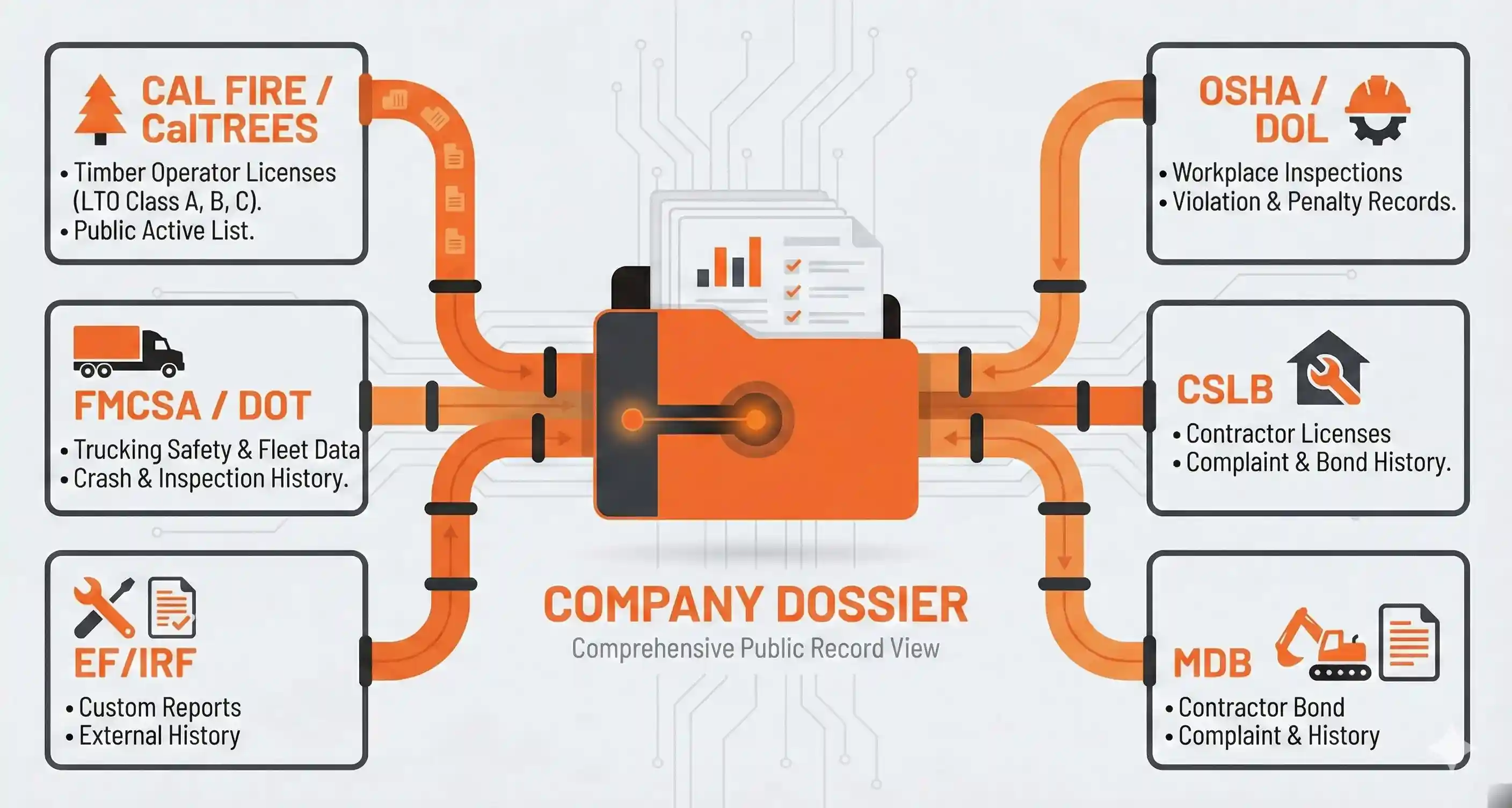
A logging company operating in California touches at least four separate government databases before they ever fall a single tree:
- CAL FIRE CalTREES: Every timber operator in California must hold a Licensed Timber Operator (LTO) permit. Class A, B, or C. The full list of active LTOs is published publicly.
- FMCSA / Department of Transportation: If they run log trucks across state lines (or even heavy commercial vehicles intrastate), they have a DOT number. That DOT number links to fleet size, safety ratings, crash history, out-of-service rates, and inspection records.
- OSHA / Department of Labor: If they've ever been inspected (and logging is one of the most inspected industries in America) there's a public record of every citation, every violation severity, every penalty assessed.
- California Contractors State License Board (CSLB): Many logging operations also hold contractor licenses for land clearing, road building, or excavation work. License status, bond amounts, complaint history, all public.
When you see all four databases for the same company, you get what Alex Hormozi calls a pain-point profile. The public filings are an X-ray of the business that tells you exactly what risks the business is taking. That tells you what kind of insurance they need. If you're any good at your job, you'll know how to sell them before they answer your call.
There are hundreds of companies and coaches who would happily sell you a one-size-fits-most method of finding leads. Unfortunately, this puts you in competition to close those leads with their thousands of clients. This is not what I do. I sell you systems that people in your space did not know exist. You are likely the only person who has the information that I give you. From there, you can create a product that is not personalized, but a product that is personal to the consumer.
Where the Prospect List Came From
Before I could query any databases, I needed names. In an industry where half the companies don't have websites, that's its own challenge.
The Associated California Loggers (ACL) maintains a ProLogger certification list, a publicly available directory of every certified professional logging operation in the state. It includes company names, owner/contact names, and cities. As of early 2025, there were 134 certified operations on the list.
I started there. Filtered by geography. Shasta County first (the client's home market), then the surrounding counties: Tehama, Siskiyou, Trinity, Lassen, Modoc, Del Norte. That gave me 54 companies across two tiers:
- Tier 1: 19 companies headquartered in Shasta County. Walking distance, metaphorically. These are the ones you'd meet at the local ACL chapter meeting.
- Tier 2: 35 companies in adjacent counties. Same timber market, same conferences, same mills buying their logs. A one-to-two hour drive from the client's office.
Fifty-four companies. No emails. No phone numbers yet. No idea which ones were three-person operations and which ones ran twelve crews with a $2M equipment fleet. Just names, contacts, and cities.
The databases would fill in the rest.
The Four-Database Lookup System
I built a Python script for each data source. Each one takes a company name, queries the relevant API or scrapes the relevant public page, and returns structured JSON. A master orchestrator runs all four in sequence across the full prospect list.
Here's what each one does and what it reveals.
Database 1: FMCSA (Fleet Size, Safety Rating, and Crash History)
FMCSA keeps records on every commercial motor carrier in the United States. Their API is free. You register through Login.gov, generate a WebKey, and you're querying carrier data within minutes.
import requests import os FMCSA_BASE = "https://mobile.fmcsa.dot.gov/qc/services" def search_carrier(company_name, api_key, state="CA"): """Search FMCSA for a carrier by company name.""" url = f"{FMCSA_BASE}/carriers/name/{company_name}" params = {"webKey": api_key, "stateAbbrev": state} response = requests.get(url, params=params) if response.status_code == 200: data = response.json() carriers = data.get("content", []) return carriers return [] def get_carrier_details(dot_number, api_key): """Pull full carrier profile by DOT number.""" url = f"{FMCSA_BASE}/carriers/{dot_number}" params = {"webKey": api_key} response = requests.get(url, params=params) if response.status_code == 200: return response.json().get("content", {}) return {}
What this returns for a logging company:
- Total power units and drivers tell you fleet size, which directly correlates to premium volume. A company with 12 trucks is a very different insurance opportunity than one with 2.
- Safety rating (Satisfactory / Conditional / Unsatisfactory). A conditional or unsatisfactory rating means they're having trouble getting placed with standard carriers. That's a pain point.
- Out-of-service rates. If their vehicle OOS rate is above the national average (~21% for trucks), they're getting pulled off the road at inspections. Their commercial auto premiums are probably painful.
- Crash history covers any recordable crashes in the last 24 months. Each one is an insurance event that affects their loss history.
- BASIC scores (Unsafe Driving, Hours of Service, Vehicle Maintenance, etc.) are percentile scores that tell you exactly where their fleet is struggling. A high Vehicle Maintenance BASIC means their equipment is failing inspections. That's an inland marine and commercial auto conversation.
What's weird is that a company with high OOS rates and a large fleet is a better prospect than a clean one. Not worse. The ideal client for someone who manages risk is a person with lots of assets and bad decision-making. They're the ones who need a specialist agent who can navigate hard-to-place commercial auto and pair it with loss control services. They're probably getting non-renewed by their current carrier right now.
Database 2: OSHA (Inspection History and Violation Severity)
Logging is the most dangerous occupation in America by fatality rate. OSHA knows this, and they inspect accordingly. The DOL Open Data Portal provides API access to federal inspection records.
DOL_BASE = "https://data.dol.gov/get" def search_osha_inspections(company_name, api_key): """Search OSHA inspection records by establishment name.""" search_name = company_name.replace(",", "").replace(".", "") url = f"{DOL_BASE}/inspection" headers = {"X-API-KEY": api_key} params = { "$filter": f"contains(estab_name,'{search_name}')", "$select": "activity_nr,estab_name,site_city,site_state," "open_date,close_case_date,insp_type," "total_initial_penalty,total_current_penalty", "$top": 50 } response = requests.get(url, headers=headers, params=params) if response.status_code == 200: return response.json() return []
California runs its own OSHA program (Cal/OSHA). Federal OSHA data may not capture all California inspections. The state plan records have a different reporting pipeline. My script notes this on every dossier. An empty federal OSHA result doesn't mean a clean record. It means you need to check the state database too. I flagged this as a manual verification step, because missing opportunities this huge is worth my attention.
What OSHA data reveals:
- Serious violations directly impact experience modification rates (EMR), which drive workers' compensation premiums. A company with recent serious violations is paying more for WC than they need to, and a good agent can build a safety program that brings that mod rate down over 2-3 years.
- Willful or repeat violations are the red flag. They tell you there are systemic safety culture problems. From an insurance perspective, these companies are either getting non-renewed or paying astronomical premiums. They need help.
- Inspection type (programmed vs. complaint-driven). A complaint-driven inspection means someone (an employee, a neighbor, a competing operator) reported them. That's a different risk profile than a routine programmed inspection.
Database 3: CSLB (Contractor Licensing and Bond Status)
The California Contractors State License Board publishes their full license database as a downloadable CSV through their data portal. No API key needed. Download the License Master file, drop it in your data directory, and query locally.
import csv from difflib import SequenceMatcher def search_cslb_local(company_name, csv_path="data/cslb_license_master.csv"): """Search the local CSLB CSV for a company.""" matches = [] search_lower = company_name.lower() with open(csv_path, 'r', encoding='utf-8', errors='replace') as f: reader = csv.DictReader(f) for row in reader: business_name = row.get("BUSINESS_NAME", "").lower() # Fuzzy match because company names differ across databases ratio = SequenceMatcher( None, search_lower, business_name ).ratio() if ratio > 0.75 or search_lower in business_name: matches.append({ "license_number": row.get("LICENSE_NBR"), "business_name": row.get("BUSINESS_NAME"), "classification": row.get("CLASSIFICATION"), "status": row.get("LICENSE_STATUS"), "city": row.get("CITY"), "issue_date": row.get("ISSUE_DATE"), "expire_date": row.get("EXPIRE_DATE"), "bond_amount": row.get("BOND_AMOUNT"), }) return matches
Not every logging company holds a CSLB license. Many operate solely under their LTO. But the ones that do often hold C-61 (Limited Specialty) licenses for land clearing, grading, or road building. This tells us they need diverse insurance coverage. When I talked to the client during the audit, he helped me quantify how to figure out what kinds.
If a company doesn't show up in CSLB, that doesn't tell you much on its own. But combined with the other three databases, it helps you understand the shape of the operation.
Database 4: CalTREES (Licensed Timber Operator Status)
CalTREES is CAL FIRE's timber regulation system. The LTO list is published publicly and includes every Licensed Timber Operator in California: their license number, class (A, B, or C), status, and name.
import requests from bs4 import BeautifulSoup LTO_LIST_URL = ( "https://aca-prod.accela.com/Caltrees/" "customization/common/licenseList.aspx" ) def fetch_lto_list(): """Fetch and parse the full LTO list from CalTREES.""" response = requests.get(LTO_LIST_URL) soup = BeautifulSoup(response.text, 'html.parser') records = [] table = soup.find('table') if table: rows = table.find_all('tr')[1:] # Skip header for row in rows: cells = row.find_all('td') if len(cells) >= 4: records.append({ "license_number": cells[0].text.strip(), "name": cells[1].text.strip(), "license_type": cells[2].text.strip(), "status": cells[3].text.strip(), }) return records def match_prospect_to_lto(company_name, contact_name, lto_records): """Fuzzy match a prospect against the LTO list.""" matches = [] for record in lto_records: name_lower = record["name"].lower() if (company_name.lower() in name_lower or contact_name.lower() in name_lower): matches.append(record) return matches
LTO class matters for the insurance conversation:
- Class A operators can plan and supervise timber operations. These are the full-service operators, the ones running multiple crews. Largest premium opportunities.
- Class B can supervise but not plan. Mid-size operations.
- Class C covers timber fallers only. Smaller operations, but often the most dangerous work. Workers' comp is their biggest insurance line.
The Orchestration Layer
Here's where I stop showing you everything.
The four lookup scripts above are the 80%. They're public APIs hitting public databases. Anyone with a Python environment and a free afternoon could build them. I've shown you the exact endpoints, the exact parameters, the exact parsing logic.
What I'm not going to show you is how the results get assembled.
The orchestration layer, the script that takes the raw JSON from all four sources and synthesized it into the project dossier that met client specifications, is the 20% that makes this a business instead of a tutorial.
I'll tell you what it produces:
For each of the 54 companies, the system generates a structured markdown dossier that includes:
- A data summary from each source (found/not found, key findings)
- A pain-point matrix mapping every discovered issue to a specific insurance conversation
- A recommended "door opener," the single most compelling reason to call
- A priority score based on estimated premium volume and placement difficulty
- An outreach method recommendation (cold call, conference introduction, mutual referral)
The full run across all 54 companies takes about 15-20 minutes, mostly rate-limited by the API calls. At the end, you have a master intelligence report that would take a human researcher weeks to assemble. And they still wouldn't have the cross-referenced pain-point analysis.
A few structural decisions that matter:
Fuzzy matching is essential. Company names are never consistent across government databases. "J A Headrick, Inc." in CSLB might be "Headrick Logging" in FMCSA and "James Headrick" on the CalTREES LTO list. The scripts use a combination of difflib.SequenceMatcher, substring matching, and contact-name cross-referencing to handle this. Getting this wrong means missing data that exists.
"No hit" doesn't mean "clean." A company that doesn't appear in FMCSA might simply run trucks intrastate only. A company with no OSHA record might never have been inspected, or might have all their records in the Cal/OSHA system instead of the federal database. The dossier builder treats every negative result as something worth annotating, not as a blank field to skip.
Rate limiting is non-negotiable. These are government APIs serving the public interest. I built in 1-2 second delays between requests, exponential backoff on failures, and hard stops if a source returns errors. You don't hammer these endpoints. Ever.
How the Pain-Point Matrix Got Built
The scripts took a weekend. The intelligence layer took two more days of sitting with the client.

There's something missing from this code. I don't know anything about timber insurance. I didn't know that an elevated OSHA violation history means a company's experience modification rate is inflated, which means their workers' compensation premiums are higher than they need to be, which means there's a specific three-year loss control conversation that a good agent can walk into. I didn't know that a high vehicle out-of-service rate is a commercial auto placement problem that most generalist agents don't know how to solve. I certainly didn't know that these are the money.
But my client knew all of that. He's the one who looked at my summary on the database output and said "this variable matters, this one doesn't, and here's why." Every row in the pain-point matrix exists because an insurance professional looked at a compliance record and said "I've seen that claim before."
This part does not scale with code. You can automate the data collection. You can automate the cross-referencing. But the logic that drives how you run this business opportunity comes from someone who's had a thousand of those conversations already.
The entire system, from first API call to finished dossiers for 54 companies, took four days. Not four months. Not four sprints. Four days of conversations and work between someone who can build automated systems and someone who understands the insurance market those systems needed to serve.
I bring the how, you bring the why. We build something together that neither of us could build alone, and when it's done, you have a system that thinks the way you think. And, every time you want to have a new thought, you're twenty minutes away from genius.
What the Pain-Point Matrix Looks Like
Without showing you the scoring logic, I can show you the mapping. This is the conceptual framework that turns raw database records into sales intelligence:
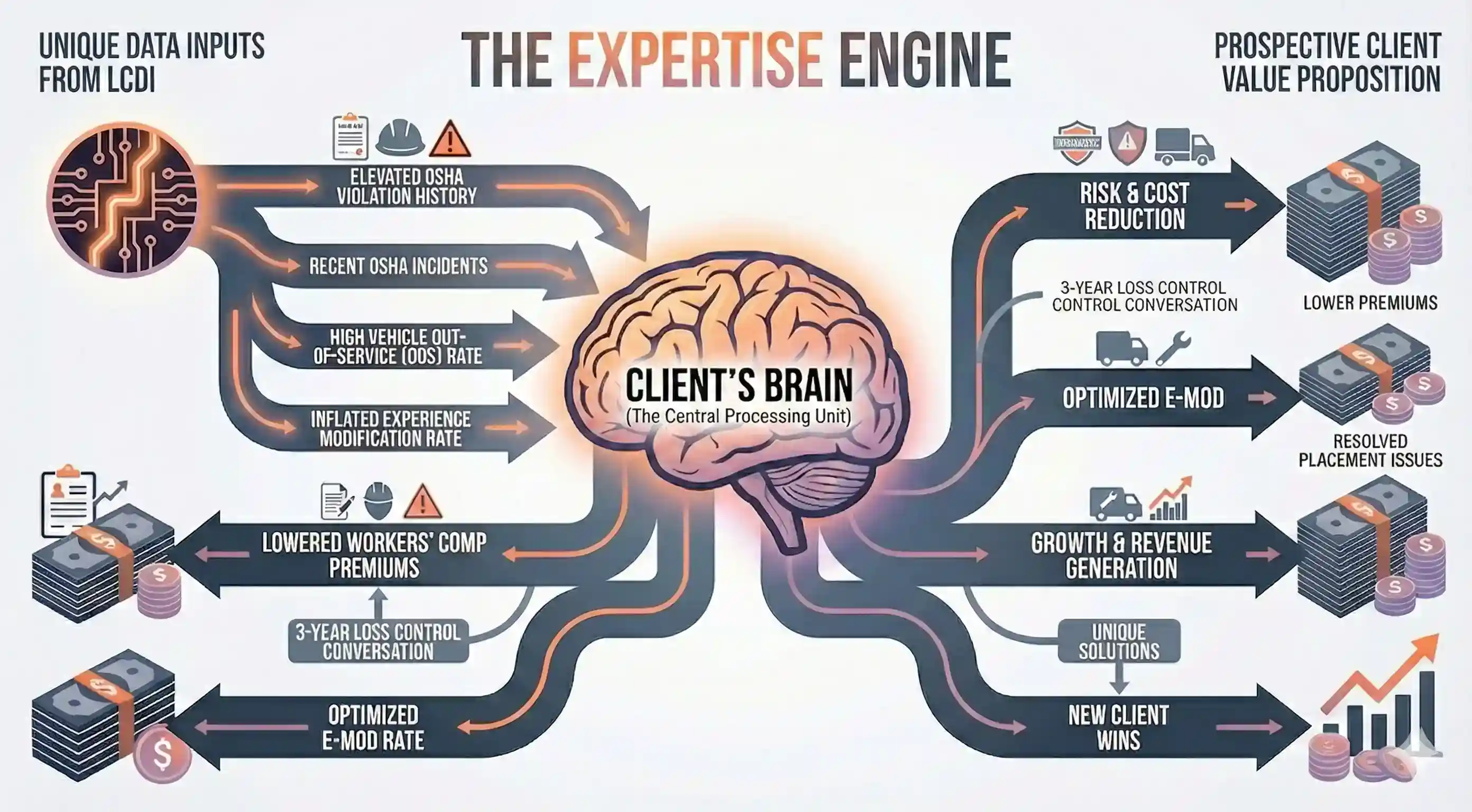
| Discovery | What It Means | Insurance Conversation |
|---|---|---|
| OSHA serious violations in last 3 years | EMR is elevated, WC premiums are inflated | "Your experience mod is costing you $X/year. Here's a 3-year loss control plan to bring it down." |
| FMCSA vehicle OOS rate >21% | Fleet is failing roadside inspections | "You're getting pulled off the road. That's a commercial auto placement problem and a loss control problem. Both are solvable." |
| Class A LTO + large fleet + no evident agent relationship | Full-service operation that's either self-insured or with a generalist agent | "Most timber operations need 5-7 policy lines working together. Is your current agent a timber specialist?" |
| CSLB license for land clearing + LTO for timber | Diversified operation with multiple risk profiles | "You're running two businesses under one roof. Are they insured like two businesses, or are there gaps between your GL programs?" |
| High equipment value + no FMCSA record | Significant inland marine exposure, trucks may be intrastate only | "Your feller bunchers and processors are probably your most expensive assets. When's the last time someone appraised your equipment schedule?" |
The actual system scores these on severity, recency, and estimated premium impact, then ranks the 54 prospects by overall opportunity score. The top 10 get "call this week" flags. The next 15 get "conference approach" flags. The rest get queued for drip outreach.
What Other People Are Doing (And Where This Goes Further)
It's worth understanding how this approach differs from what's available in the market. There are four categories of existing tools:
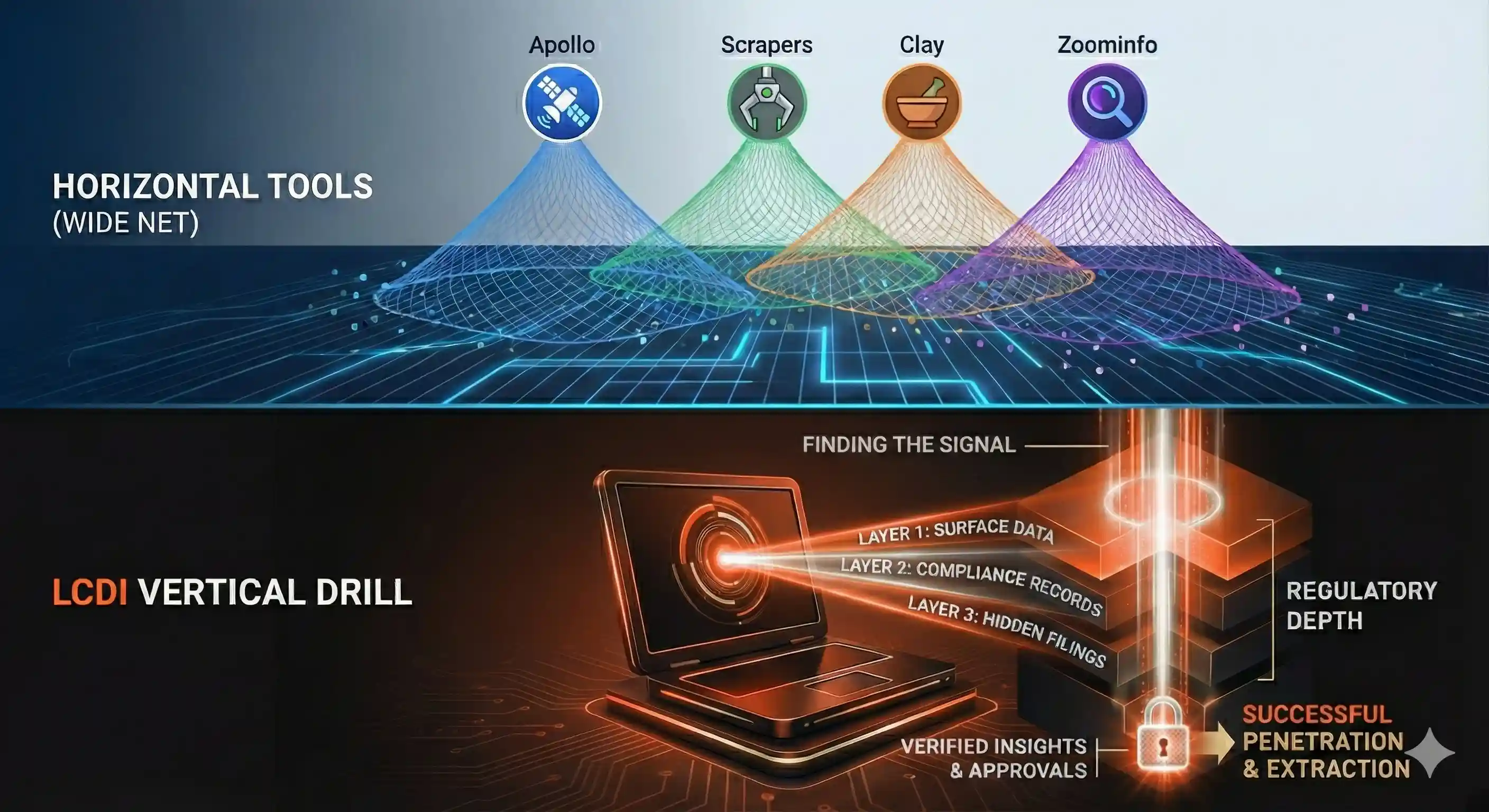
- Lead databases like Apollo, ZoomInfo, LinkedIn Sales Navigator, and Cognism aggregate contact information from the digital footprint: LinkedIn profiles, company websites, CRM data sharing, web scraping. Excellent for industries where prospects exist online. Completely blind to industries where they don't. My 54 logging companies have an average of zero LinkedIn profiles among their ownership.
- Enrichment platforms like Clay and Clearbit take a name or email and layer on additional data: company size, tech stack, funding history, news mentions. Clay is probably the best tool in this space; it chains 150+ data providers in waterfall sequences and lets you build complex enrichment workflows. But it enriches what already exists digitally. If there's no digital signal to enrich, it returns nothing.
- Intent data from platforms like Bombora and 6sense track which companies are researching topics related to your product. If a VP of Operations at a mid-market company starts reading articles about "commercial fleet insurance," the intent signal fires and you get notified. Powerful for enterprise sales. Completely useless for an industry where the research happens at an ACL chapter meeting over coffee, not on the internet.
- Web scraping as described by Scrapus and similar platforms, where software crawls the open web for company information, extracts structured data, and matches it against ideal customer profiles. This is the closest conceptual cousin to what I built. The difference is that Scrapus and its peers are horizontal. They scrape whatever's on the web. My system is vertical. It queries specific government databases that contain regulatory compliance data with direct insurance relevance. Web scraping would have found maybe 10 of the 54 companies. Government database queries found all of them.
Enrichment Layers I'd Add for a Different Market
If the target market had more of a digital footprint, I'd layer additional intelligence on top:
- Clay enrichment workflows. Clay is the best tool I've seen for chaining data sources together. If I had LinkedIn profiles for these prospects, I'd run them through Clay's waterfall enrichment to pull in company size, tech stack, recent news, and verified email addresses. For this particular market, there wasn't enough digital signal to enrich. But for construction contractors in a metro area? Clay would be the second step after the government database sweep.
- Google Maps Platform API. For markets where businesses have Google Business profiles, the Places API can pull reviews, photos, hours, and phone numbers. About 30% of my 54 logging companies had any Google presence. For a construction or trucking lead gen system, this hit rate would be much higher.
- Secretary of State filings. Business entity records (formation date, registered agent, principal address) are public in every state. California's is at bizfileonline.sos.ca.gov. I didn't automate this layer because the CalTREES LTO list already gave me the core identification data. But for a market where you're trying to determine corporate structure, ownership chains, or entity status, it's a valuable addition.
- County Assessor / Property Records. For insurance lines tied to physical assets (property, equipment yards, timber stands), county assessor databases reveal property values, parcel sizes, and ownership. This would be the next enrichment layer if I were building a timber property insurance system rather than a liability and operations system.
Where This Is Heading
The academic paper on Scrapus describes using reinforcement learning to improve web crawl yield, transformer-based NLP for entity extraction, and knowledge graphs for lead scoring. That's the trajectory this kind of system is on.
For my specific use case, the next evolution would be:
- LLM-powered dossier synthesis. Instead of rule-based pain-point mapping, feed the raw data from all four sources into a language model with a system prompt that understands insurance underwriting. Let it write the dossier narrative. I've prototyped this. It works disturbingly well.
- Automated outreach drafting. Once you have a pain-point profile, generating a personalized cold email or call script is a straightforward language model task. "I noticed your FMCSA profile shows X. Companies in your position often struggle with Y. We specialize in Z." The template writes itself when you have the data.
- Trigger-based monitoring. Instead of running the system once, set it to monitor the databases for changes. New OSHA violation? New DOT inspection? LTO renewal coming up? Each event is a trigger for timely outreach. This turns a one-time lead list into a living intelligence feed.
I haven't built all of this yet. But the architecture supports it. That's the point of building vertical rather than horizontal. When you go deep into one industry's data ecosystem, every enhancement compounds.
The Numbers
We ended up finding fifty-four candidate companies. We checked them against the databases that we identified. It took about 20 minutes to run once we built it. The next county we move on to will take ten minutes to build.
A human researcher doing this manually (logging into each website, searching each company, cross-referencing results, writing up findings) would spend approximately 45 minutes per company. That's 40+ hours for the full list. And they still wouldn't have the cross-referenced scoring.
The system cost to build: my time. The ongoing cost to run: zero. The APIs are free. The databases are public. Python is free. The only scarce input was knowing which databases to query, why they mattered for this specific insurance use case, and how to turn compliance records into sales intelligence.
The last part is what I'm selling you.
What You Can Take From This
The code samples in this article are real. The API endpoints are live. The databases are public. If you're in an industry where your prospects register with government agencies, and if your industry is regulated they do, you can build a version of this system.
Here are the government databases that most B2B salespeople don't know exist:
- FMCSA Carrier Search Anyone with commercial vehicles
- OSHA Inspection Data Any employer that's been inspected
- SEC EDGAR Public companies, investment advisors, broker-dealers
- SAM.gov Any company that does business with the federal government
- USPTO Patent Search Companies with intellectual property
- FDA Establishment Registration Food, drug, and medical device manufacturers
- FCC License Search Broadcasters, wireless operators, telecom companies
- EPA ECHO Environmental compliance and enforcement data
- MSHA Mine Data Mining operations
And for California specifically:
- CSLB Contractor Search Licensed contractors
- CalTREES LTO List Licensed timber operators
- Cal/OSHA State-level inspection records
- DRE License Lookup Real estate licensees
- CDI Company Search Licensed insurance entities
Every one of these is a lead generation system waiting to be built. The data is there. The APIs are there (or the scraping targets are). You just need someone who knows what to do with it.
That's the business.
One More Thing
Everything I've described works because the lead generation industry itself can't find the people I find. The best prospects are the ones nobody else is looking for.
Every tool in the conventional stack (Apollo, ZoomInfo, LinkedIn Sales Navigator, Clay, Bombora) is optimized for the same pool of digitally-visible companies. The companies that have websites. That have LinkedIn pages. That show up in business directories. These are valid prospects. They're also prospects that every other salesperson in your industry is already contacting.
Government databases contain the other pool. The companies that exist in the physical world but barely exist on the internet. The ones whose primary business relationship is with a regulatory agency, not a social media platform. The ones who are invisible to horizontal prospecting tools because they never opted into the digital ecosystem those tools index.
In timber, that's almost the entire market. But it's true to some degree in every industry that involves physical operations, heavy equipment, regulatory compliance, or rural geography: construction, mining, agriculture, commercial fishing, trucking, manufacturing, oil and gas, maritime.
If your clients operate in any of those spaces, their prospects are registered in a government database right now. The question is whether you'll be the one who goes and finds them.
Or whether you'll keep refreshing your Apollo search and wondering why your emails aren't getting opened.
READY TO STOP WORKING SO HARD?
We build self-hosted automation systems for businesses that take their data seriously. No per-minute fees. No third-party data exposure. Only Freedom.
BOOK A 30-MINUTE CONSULTATION →