You're Renting Your AI Voice Agent. Here's Why That's a Problem.
Every platform wants you to pay per minute and trust them with your data. We break down the entire voice agent pipeline, compare every major platform, and show you exactly how we built ours on our own infrastructure.

Every AI voice agent platform wants you to believe the same thing: plug in, pay per minute, and let them handle the rest. What they don't tell you is that "the rest" includes storing your call recordings on their servers, routing your customer conversations through their infrastructure, and training their systems on your business logic.
We build AI voice agents differently. We self-host them. And after reading this, you'll understand exactly why.
This article breaks down the entire AI voice agent pipeline, compares every major hosted platform on the market, explains the technical and strategic case for running the whole stack on your own VPS, and walks you through how we actually built ours.
What an AI Voice Agent Actually Is
Before we compare platforms, you need to understand what's happening under the hood when an AI agent picks up the phone. There's no magic here. It's a pipeline of distinct technologies working in sequence, and every platform on the market assembles some version of this same chain.
The Voice Pipeline
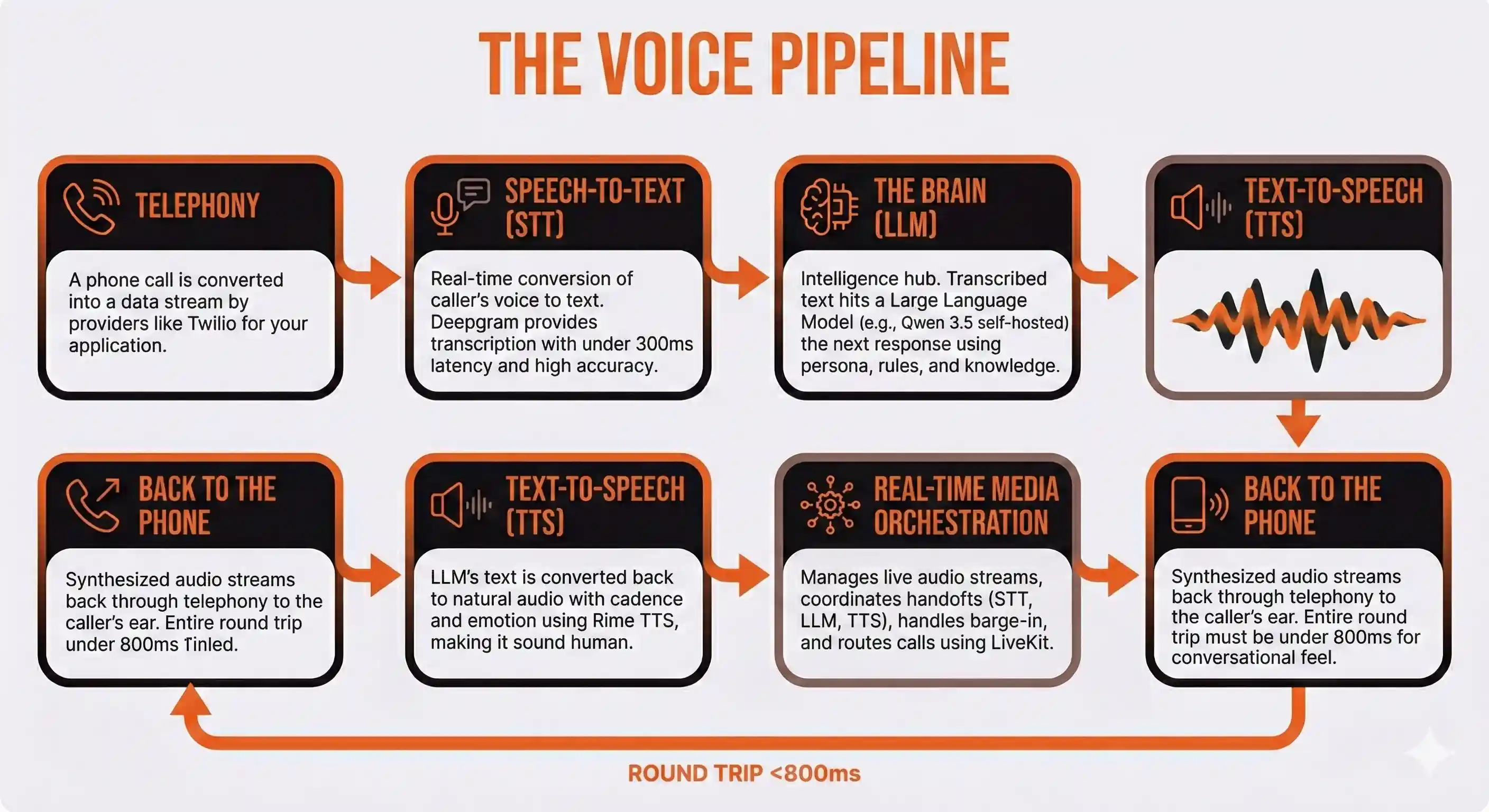
Step 1: Telephony. A phone call comes in (or goes out). The raw audio stream needs to get from the phone network to your application. This is handled by a telephony provider like Twilio. They convert the call into a data stream your server can work with.
Step 2: Speech-to-Text (STT). The caller's voice gets converted into text in real time. The agent needs to understand what was said before it can respond. Deepgram is the current leader here, with transcription latency under 300 milliseconds and strong accuracy even in noisy environments.
Step 3: The Brain (LLM). This is where the intelligence lives. The transcribed text hits a large language model, which determines what the agent should say next. The LLM has access to a system prompt that defines the agent's persona, its knowledge base, and the rules governing its behavior. This is the component that makes the conversation feel human rather than robotic. We run Qwen 3.5, an open-weight model from Alibaba Cloud released under the Apache 2.0 license, self-hosted on our own infrastructure.
Step 4: Text-to-Speech (TTS). The LLM's text response gets converted back into audio. The quality of this step determines whether your agent sounds like a person or a GPS navigator from 2008. We use Rime TTS, which produces speech with natural cadence, breathing patterns, and emotional inflection that's nearly indistinguishable from a human voice.
Step 5: Real-Time Media Orchestration. This is the layer most people don't think about, and it's the one that separates a demo from a production system. Something has to manage the real-time audio streams, coordinate the handoffs between STT, LLM, and TTS, handle barge-in (when a caller interrupts the agent mid-sentence), and route calls to the right place. We use LiveKit, an open-source real-time communication framework, as the backbone of our entire system.
Step 6: Back to the phone. The synthesized audio streams back through the telephony layer to the caller's ear. The entire round trip needs to happen in under 800 milliseconds to feel conversational. Anything slower and the caller notices an unnatural pause.
That's the pipeline. Every AI voice agent on the planet runs some version of it. The only question is who controls each piece.
The Hosted Platform Landscape
The market for AI voice agent platforms has exploded. Dozens of companies now offer various levels of abstraction over this pipeline. They range from developer-centric frameworks that let you assemble your own stack to fully managed solutions that hide the complexity entirely.
Here are the major players and what each one actually gives you.
Vapi
Vapi is the developer's playground. It's an API-first platform that gives you granular control over every component in the voice pipeline. You choose your own LLM provider, your own TTS engine, your own STT service, and your own telephony carrier. Vapi provides the orchestration layer that ties them all together.
The pitch: Maximum flexibility. Swap any component without rebuilding your agent. Sub-600ms response times. Visual flow builder for mapping conversation logic.
The reality: Vapi's advertised rate is $0.05 per minute. That's the platform fee alone. Once you add Deepgram for transcription, an LLM provider like OpenAI, a TTS provider like ElevenLabs, and Twilio for telephony, your actual cost lands between $0.23 and $0.33 per minute. Enterprise deployments typically run $40,000 to $70,000 annually. You're also managing billing relationships with four to six different vendors, each with their own pricing model and invoicing cycle.
Vapi requires serious engineering talent to deploy and maintain. Non-technical teams will struggle. The platform is powerful, but you're paying a premium for orchestration while still assembling the underlying components yourself.
Bland AI
Bland AI takes a more opinionated approach. It's built for outbound calling campaigns at scale, with features like voice cloning, conversational pathways, and dedicated GPU infrastructure for enterprise clients. Bland lets you self-host for maximum data control, which is a meaningful differentiator.
The pitch: Human-like conversations. Voice cloning from a single audio sample. Self-hosted deployment option. SOC 2 Type II and HIPAA compliant.
The reality: Base rate is $0.09 per minute for connected calls, with a minimum fee of $0.015 per outbound attempt regardless of connection. Voice cloning adds $200 to $300 per month. Users report higher latency than competitors, averaging around 800ms, and the voice quality has been described as noticeably synthetic. When callers detect they're talking to a bot within the first 20 to 30 seconds, they hang up, and you've already paid for the attempt.
Bland's self-hosting option is notable, but it's positioned as an enterprise feature with custom pricing, not something accessible to small or mid-size operations.
Retell AI
Retell has carved out a niche in compliance-heavy industries. Healthcare, financial services, and insurance companies gravitate toward Retell because it ships with HIPAA, SOC 2 Type 1 and 2, and GDPR compliance out of the box across all plans. The platform supports 31 languages and emphasizes structured conversation flows with built-in testing tools.
The pitch: $0.07 per minute with everything bundled. 99.99% uptime SLA. Unlimited concurrent call capacity. PII redaction built in.
The reality: Retell is the most transparent on pricing among the major platforms. The $0.07 per minute rate actually includes most of the components that Vapi charges separately for. The platform is still developer-oriented, but less aggressively so than Vapi. The tradeoff is less flexibility in component selection. You're using Retell's chosen providers for STT, TTS, and LLM inference, which means you can't easily swap in a model or engine that better fits your use case.
For regulated industries where compliance is non-negotiable and the budget exists for per-minute billing at scale, Retell is the most complete out-of-the-box solution.
Synthflow
Synthflow positions itself as the no-code alternative. Visual flow builder, flat-rate pricing, built-in analytics, voice cloning, and native CRM integrations with HubSpot, Salesforce, GoHighLevel, and 200+ other platforms via Zapier.
The pitch: Everything included in one subscription. No vendor management. No engineering required. Plans from $29 to $1,499 per month depending on volume.
The reality: Synthflow delivers on simplicity. If your goal is to get a basic voice agent running with minimal technical investment, it's genuinely the fastest path. The tradeoff is that you're locked into Synthflow's entire stack. You can't swap out the LLM for a model better suited to your domain. You can't optimize individual pipeline components. And your conversation data, your prompts, and your business logic all live on Synthflow's infrastructure.
For businesses that need a quick deployment and don't have deep technical requirements, Synthflow works. But you're trading long-term control for short-term convenience.
The Platform Pricing Illusion
Here's what every hosted platform comparison article glosses over: the per-minute pricing model is designed to scale against you.
Consider a modestly busy voice agent handling 5,000 minutes of calls per month. That's roughly 170 calls averaging three minutes each. At different platforms' effective per-minute rates, your monthly costs look like this:
| Platform | Effective Rate | Monthly (5,000 min) | Annual Cost |
|---|---|---|---|
| Vapi (fully loaded) | ~$0.28/min | $1,400 | $16,800 |
| Bland AI | ~$0.12/min | $600 | $7,200 |
| Retell AI | ~$0.07/min | $350 | $4,200 |
| Synthflow | ~$0.08/min | $400 | $4,800 |
| Self-Hosted | ~$0.02/min | $100 | $1,200 |
Those numbers don't account for scaling. Double your call volume and the hosted platforms double your bill. A self-hosted solution's marginal cost per additional minute is nearly zero once your infrastructure is in place.
But cost isn't even the most important consideration. Data sovereignty is.
The Data Problem Nobody Talks About

Every call your AI voice agent handles generates data. Lots of it.
There's the raw audio recording. The real-time transcript. The LLM's reasoning chain. The metadata about call duration, sentiment, and outcomes. Your system prompt, which contains your proprietary business logic, persona definitions, and domain knowledge. Your CRM integration data, which includes client names, case details, financial information, and whatever else your agent needs to do its job.
When you use a hosted platform, all of that data passes through their infrastructure. In most cases, it's stored there too.
Read the terms of service carefully. Most platforms reserve the right to use aggregated or anonymized data to improve their services. Some are more explicit about it than others. But the fundamental issue isn't about any individual platform's privacy policy. It's structural.
When your data leaves your infrastructure, you lose control over it. You're trusting that a third-party startup, funded by venture capital and incentivized to grow at all costs, will prioritize your data security over their own business interests. You're trusting that they won't be acquired by a larger company with different privacy standards. You're trusting that their security practices are as strong as they claim. You're trusting that a breach won't expose your client conversations.
For businesses in regulated industries, this isn't theoretical risk management. It's a compliance liability.
For everyone else, it's a competitive intelligence issue. Your system prompts describe how you run your business. Your conversation transcripts reveal your sales process, your objection handling, your pricing strategies, and your client relationships. That information has value. On someone else's server, you have no guarantee about who can access it or how it might be used.
Our Architecture: How We Actually Built It
Enough theory. Here's what our production voice agent looks like.
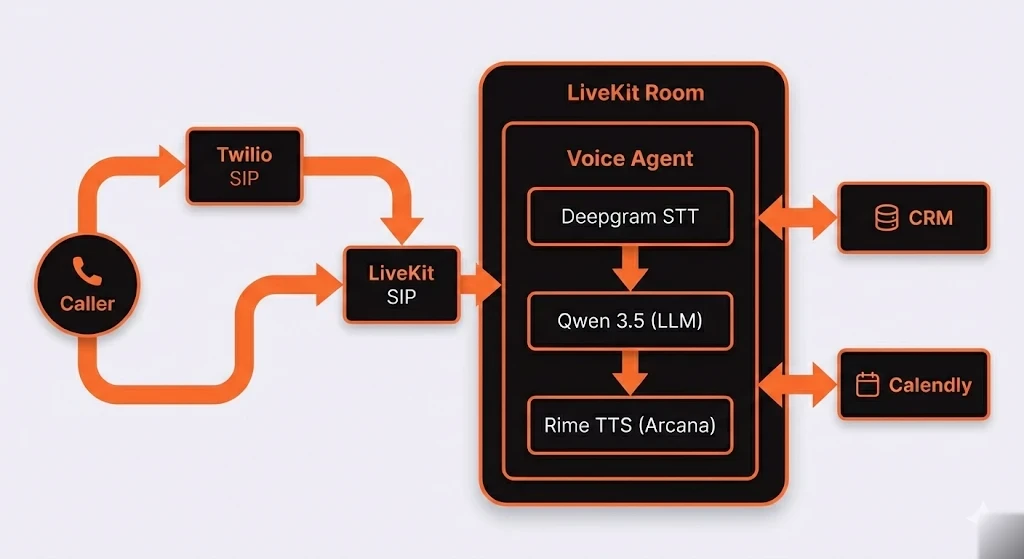
All components except the Deepgram, Rime, and Qwen inference APIs run on a single VPS. No third party sees the full conversation. STT receives audio fragments. TTS receives response text. The LLM receives conversation text. None of them see each other's data or have the full picture of the interaction.
That isolation is by design. Even though we use external APIs for STT and TTS, no single vendor has enough context to reconstruct a complete conversation. The orchestration happens on our server, which means the only place the full picture exists is infrastructure we control.
Why LiveKit
LiveKit is the piece that makes the whole system work in real time. It's an open-source WebRTC media server that handles the hard problems of voice communication: low-latency audio streaming, room-based call routing, SIP integration, and participant management.
When a call arrives via Twilio, it's bridged through LiveKit's SIP connector into a LiveKit room. The voice agent joins that room as a participant, just like a human would join a video call. The agent listens to the caller's audio stream, processes it through the STT-LLM-TTS pipeline, and sends its response back into the room as audio.
This architecture gives us several things for free that hosted platforms charge premiums for. Call recording happens at the room level. Multiple agents or human operators can join a call mid-conversation. Call transfers work natively through SIP REFER. And because LiveKit is open source and self-hosted, there are no per-minute platform fees for the orchestration layer.
The LLM: Self-Hosted Intelligence
Qwen 3.5 is an open-weight model from Alibaba Cloud, released under the Apache 2.0 license. It uses a Mixture-of-Experts architecture with 397 billion total parameters but only activates roughly 17 billion per token during inference. That means frontier-level reasoning capability without needing a server room full of GPUs.
When your LLM runs on your own infrastructure, several things change fundamentally:
No per-token billing. Every API call to a cloud LLM provider costs money based on input and output tokens. When you self-host, your cost is fixed infrastructure regardless of how many conversations your agent handles.
Your prompts stay private. Your system prompt is your intellectual property. It defines your agent's persona, its knowledge, its behavior rules, and its domain expertise. Self-hosting means your prompts never leave your server.
No rate limits. Cloud providers throttle requests during peak demand. When your voice agent needs sub-second responses to maintain conversational flow, a rate limit tanks the entire experience.
Fine-tuning control. Open-weight models can be fine-tuned on your domain data. A voice agent handling legal case updates can be tuned to understand legal terminology, case management workflows, and client communication patterns. That fine-tuned model becomes a proprietary asset that compounds in value over time.
CRM and Scheduling Integration
The orchestration layer connects directly to your CRM and scheduling platform via their APIs. Before the agent handles a call, it queries the CRM for relevant context: case status, recent updates, outstanding issues. After the call, the transcript and outcomes post back to the appropriate record automatically.
Scheduling works the same way. When a caller needs to book an appointment, the agent checks real-time availability through the scheduling API and confirms the booking within the same conversation. No "someone will call you back." No missed follow-ups.
These integrations run server-to-server on your infrastructure. Your CRM data doesn't route through a third-party platform.
What It Actually Costs
Here's our real monthly spend at approximately 1,950 minutes of call volume:
| Service | Monthly Cost |
|---|---|
| Deepgram STT (Nova-3) | ~$7 |
| Rime TTS (Arcana) | ~$59 |
| Twilio phone number | $1 |
| Twilio per-minute | ~$15 |
| Total | ~$82/month |
The LLM runs on the VPS at no additional per-call cost. That's the self-hosting dividend. Whether the agent handles 100 calls or 10,000, the LLM inference cost doesn't change.
Rime is the largest line item. Their Arcana model produces the most natural-sounding speech, but if cost is a concern, their Mist model cuts the TTS rate from $0.03/min to $0.02/min with only a slight reduction in expressiveness.
At roughly $0.04 per minute all-in (excluding fixed VPS costs), compare that to the $0.07 to $0.33 per minute the hosted platforms charge. At 5,000 minutes monthly, you're saving anywhere from $150 to $1,300 per month. At 20,000 minutes, the gap becomes enormous.
The Deployment: Key Steps
Standing up this stack isn't a weekend project for someone who's never touched a Linux server, but it's also not rocket science. Here's the high-level process.
Infrastructure
You need a VPS with a privacy-conscious hosting provider. We use European hosting for the stronger data sovereignty protections. You'll also need a domain name with DNS access to create an A record pointing a subdomain (something like livekit.yourdomain.com) at your VPS for TLS certificate provisioning.
Firewall Configuration
The stack requires several ports beyond standard HTTPS: TCP ports for LiveKit's WebSocket connections and fallback transport, UDP ports for SIP signaling and RTC media. The media port range is wide (tens of thousands of ports) because real-time audio requires dedicated UDP channels for each concurrent call.
Getting the firewall right is one of the most common failure points. If your agent isn't picking up calls, this is the first place to look.
The Docker Stack
The entire system runs as a set of Docker containers orchestrated with Docker Compose:
LiveKit Server handles the real-time media routing and room management. It's configured via a YAML file that defines API keys, TURN server settings, and SIP integration parameters.
LiveKit SIP bridges between the telephony world (Twilio) and the WebRTC world (LiveKit rooms). When a call comes in from Twilio, this service converts the SIP audio stream into a LiveKit room participant.
The Voice Agent is your custom application. It joins LiveKit rooms as a participant, listens for audio, runs it through the STT-LLM-TTS pipeline, and sends responses back. This is where your system prompt, persona, CRM integration logic, and business rules live.
Caddy sits in front as a reverse proxy, handling TLS termination and HTTPS routing via automatic Let's Encrypt certificates.
Redis provides the pub/sub messaging layer that LiveKit depends on.
A setup script generates the necessary API keys and creates your environment configuration template. From there, you populate it with your API keys for Deepgram, Rime, Twilio, your CRM, and your scheduling platform.
SIP Trunk Configuration
This is where Twilio connects to LiveKit. You create a SIP trunk in Twilio's console with an origination URI pointing at your VPS, set up SIP credentials for authentication, and associate your phone number with the trunk. Then you configure LiveKit's SIP connector to accept inbound calls from Twilio and route them into rooms where your agent is waiting.
You'll also configure an outbound trunk if your agent needs to transfer calls to a human (connecting a caller to an attorney, for example). LiveKit handles this natively through SIP REFER.
Launch and Test
Once the Docker stack is running and the SIP trunks are configured, you call your Twilio number from your cell phone. The agent should pick up within two to three seconds. Test the conversation flow, verify CRM lookups are working, confirm that call transfers connect properly, and check that transcripts are posting to the right places.
Voice Selection
Rime offers multiple voice profiles with different characteristics. For a professional context, you want something calm and clear. Rime's voice library lets you audition options before committing. Changing the voice is a single configuration change in your agent code.
Why Hosted Platforms Still Make Sense (Sometimes)
Self-hosting isn't the right answer for every business. Here's when a hosted platform genuinely serves you better:
You need to be live in 48 hours. If speed of deployment is your only priority and you need a working agent this week, Synthflow or Retell will get you there faster than standing up your own infrastructure.
You don't have technical resources. Self-hosting requires someone who can manage a Linux server, debug WebSocket connections, and troubleshoot audio encoding issues. If you don't have that person on staff or on retainer, a managed platform removes that operational burden.
Your call volume is very low. If you're running 500 minutes per month, the cost differential between hosted and self-hosted doesn't justify the infrastructure management overhead. The breakeven point where self-hosting makes economic sense is typically around 2,000 to 3,000 minutes monthly.
You genuinely don't care about data sovereignty. Some businesses handle non-sensitive information and operate in unregulated industries. If your voice agent is confirming appointment times for a hair salon, the data privacy argument carries less weight.
For everyone else, particularly businesses handling client data with any sensitivity, professional services firms, healthcare providers, financial advisors, legal practices, and any company whose competitive advantage lives in their processes and relationships, self-hosting is not just cheaper. It's smarter.
The Hidden Strategic Advantage
Beyond cost savings and data privacy, self-hosting creates a compounding strategic advantage that hosted platform users can never replicate.
Your agent gets smarter over time, and that intelligence stays yours. Every conversation your self-hosted agent handles generates training data that you own. Over months and years, you accumulate a dataset of domain-specific interactions that can be used to fine-tune your model. The agent learns your terminology, your workflows, your clients' common questions, and your preferred communication patterns. That institutional knowledge becomes a moat.
A competitor using Vapi or Bland can replicate your tech stack in a weekend. They cannot replicate the thousands of conversations that trained your model to handle your specific business context.
You control the upgrade path. When a better open-weight model releases (and they release constantly), you can swap it in on your own timeline. No waiting for a platform to support it. No negotiating with a vendor. No migration project. You download the new model, test it against your existing performance benchmarks, and deploy it when you're ready.
Qwen releases major model updates every few months. Each generation brings meaningful improvements in reasoning, instruction-following, and efficiency. Self-hosting means you capture those improvements immediately rather than waiting for a platform provider to integrate them.
You can extend without permission. Want your voice agent to also send follow-up text messages? Handle multilingual calls? Integrate with a proprietary internal system? On a hosted platform, you're limited to what their API exposes. On your own infrastructure, you write the code and deploy it. No feature request tickets. No waiting on a product roadmap. No paying for a premium tier to unlock functionality you could build yourself in an afternoon.
The Bottom Line
The AI voice agent market wants you to believe that building is hard and renting is easy. That's partially true. Renting is easier to start. But it's more expensive to scale, it puts your data in someone else's hands, and it creates a dependency on a vendor whose interests may not always align with yours.
Self-hosting is harder to set up. But once it's running, you own every piece: the infrastructure, the model, the data, the prompts, and the intelligence your agent accumulates over time.
You're not paying per minute to use your own technology. You're not sending your client conversations to a third-party server. You're not waiting for a platform to add features you need today. And you're building an asset that appreciates in value rather than a cost center that scales linearly with your success.
That's the difference between renting and owning.
READY TO STOP WORKING SO HARD?
We build self-hosted automation systems for businesses that take their data seriously. No per-minute fees. No third-party data exposure. Only Freedom.
BOOK A 30-MINUTE CONSULTATION →